
Caroline Lemieux is a final-year PhD candidate, at the University of California, Berkeley. In her research, Caroline builds tools and techniques that help make software more correct, performant, and secure, with a particular focus on fuzz testing or fuzzing tools. At FuzzCon Europe 2020, Caroline Lemieux joined us to talk about how she expanded the application domains of coverage-guided fuzzing – in particular, to find specific types of bugs (e.g. performance bugs) and explore programs more deeply.
The video is a recording of Caroline Lemieux’s talk at FuzzCon Europe 2020.
What Is Coverage-Guided Fuzzing?
Over the past few years, we have seen coverage-guided fuzzing emerge as one of the most useful tools to help developers build secure software. Coverage-guided fuzzing tools automatically find inputs that trigger bugs – often security vulnerabilities – in software
Sometimes called “coverage-guided mutational fuzzing”, this input generation technique works as follows:
- New inputs are generated by mutating existing inputs. Usually these mutations are at the byte level: flipping, deleting, duplicating, or adding random subsequences of bytes
- Mutant inputs are judged to be interesting if they cover new program behavior, usually branch coverage of the program.
- Those interesting mutants are saved to the set of existing inputs, and we go back to step 1 until timeout. The saving of inputs with new coverage is the “coverage-guided” part of the algorithm
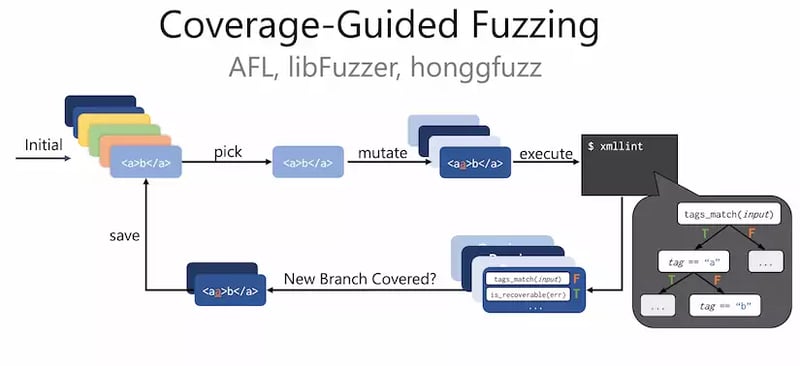 This is a form of greybox fuzzing. The term “greybox” comes from the fact that the program under test is not a total blackbox (we see some information about the components that have been covered) but also that we don’t assume total whitebox information about the code (we don’t need to be able to perfectly analyze). Instead, it’s lightweight instrumentation that quickly gives us approximate coverage information at testing time.
This is a form of greybox fuzzing. The term “greybox” comes from the fact that the program under test is not a total blackbox (we see some information about the components that have been covered) but also that we don’t assume total whitebox information about the code (we don’t need to be able to perfectly analyze). Instead, it’s lightweight instrumentation that quickly gives us approximate coverage information at testing time.
Alleviating Performance Problems
We have all been there: You run a piece of software, and everything seems fine. But, in some particular configuration, or under some particular input, there is a huge performance impact! These performance bottlenecks can not only be annoying, they are also often very expensive for your machines. They can even cause security vulnerabilities: If you have a deployed service with a severe performance issue, an attacker can launch a denial-of-service attack by sending a carefully constructed input that causes all the memory or all the CPU to be used up on the remote machine.
We built PerfFuzz to help alleviate such problems. PerfFuzz’s goal is to find test inputs that trigger algorithmic performance bottlenecks within a program. The key idea is to find inputs which maximize hit counts for different “performance components” of the program under test. For example, in a program we tested whose core functionality relied on a linked-list hash table, PerfFuzz automatically found the worst-case inputs that caused the hashtable to degrade to a linked list.
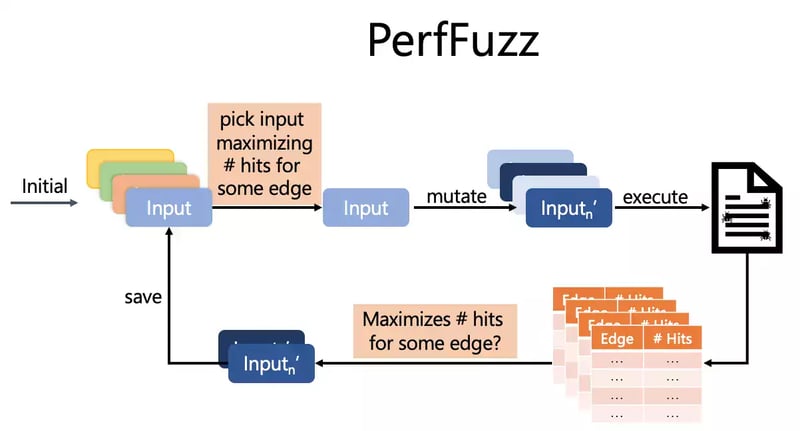
Engineering PerfFuzz
PerfFuzz is an Open Source research project that's built on top of AFL. However, the concept can be built into libFuzzer as well.
When we run a program with AFL’s regular “greybox”-coverage instrumentation, we get information about coverage of all the edges of the control flow graph of the program (branches, function calls, and returns - all that fun stuff). In PerfFuzz expanding this instrumentation, we get detailed hit counts of all these control flow graph edges. Now we know whether a particular mutant input caused a loop to be hit more times than the parent input.
With this information, we can now build an algorithm that consistently finds inputs causing performance bottlenecks. It works just like coverage-guided fuzzing, but instead of saving inputs that are “interesting” because they have new coverage, we save inputs that increase the hit count for some control-flow-graph edge. Then, to make progress, we pick inputs for the mutation if they maximize the hit counts for some edge (out of all the saved inputs).
Beyond showing the worst-case in a linked-list hash table, PerfFuzz also found quadratic performance worst-cases in a URL regex matcher, an XML parser, and super-linear behavior in the Google Closure Compiler.
FuzzFactory in a Nutshell
One thing we noticed while building PerfFuzz, is that this algorithm is a lot more general than it lets on. While we only mentioned maximizing hit counts for control-flow-graph edges, the algorithm should work for any other sort of problem we can cast as maximizing values for some keys. The neat thing about this is that if we have an algorithm that can maximize values for keys, we can solve many other problems. For example, we can find inputs that cause excessive memory allocation by maximizing the amount of allocated memory.
With that in mind, we decided to build FuzzFactory. FuzzFactory is also built on top of AFL. It comes with an afl-showdsf tool that allows you to access domain-specific feedback of your inputs. FuzzFactory contains an even more generalized version of the PerfFuzz algorithm, which can not only try to maximize key-value maps, but can also handle different notions of “interesting”, like minimizing the values in the maps, taking set union of the values, etc. What really sets it apart though, is the ability for users to more easily create these domain-specific feedback maps.
In FuzzFactory, we separate the search algorithm that is trying to maximize (or minimize, or set union) these domain-specific feedback maps from the domain-specific instrumentation which creates those maps. FuzzFactory provides multiple macros for populating these domain-specific feedback maps that can be inserted manually or automatically via llvm pass. Since this algorithm is agnostic of maps’ content, you can throw more domain-specific feedback maps at it, making it easy to compose together instrumentations to reach a more powerful fuzzer.
/* Creates a new DSF map 'name' with 'size' keys,
* 'reducer' function, and 'initial' aggregate value.
*
* To be called at the top-level global scope.
*/
FUZZFACTORY_DSF_NEW(name, size, reducer, initial)
/*Set dsf[k] = max(dsf[k],v);*/
FUZZFACTORY_DSF_MAX(dsf, k, v)
/*Set dsf[k] = dsf[k] | v; */
FUZZFACTORY_DSFBIT(dsf, k, v)
/*Set dsf[k] ? v; */
FUZZFACTORY_DSF_SET(dsf, k, v)
/* Set dsf[k] ? dsf[k] + v; */
FUZZFACOTIRY_DSF_INC(dsf, k, v)“Deeper Exploration”
Many of the programs we fuzz can be considered to have two phases: first, input validation which parses the input into some intermediate data structure, and then core logic which actually conducts the business logic of a program. In a compiler, for example, the input validation might be the syntax checking phase, while the core logic is the actual optimization and code generation.
When we hear that fuzzers aren’t able to find “deep” bugs, typically what we really mean is that they aren’t able to get into the core logic. If you have written a fuzz driver that has both these stages, it is often the case that the fuzzer’s exploration is limited to the input validation stage! One of the big reasons why fuzzers often fail to get into the core logic is because of the mutations they use to generate inputs. In standard coverage-guided fuzzing, we mutate inputs by doing byte flips and mutations at the byte level.
Let’s say you have an XML parser where you have these hard validation branches and you need the tags in your XML document (e.g. <foo> and </foo>) to match. If you start with the seed input, this is satisfied. However, if you're doing mutations at the byte level, you'll find that many of the mutants you generate no longer satisfy these hard to hit branches in the input validation stage. This is why you're never going to get deeper into exploring the core logic.
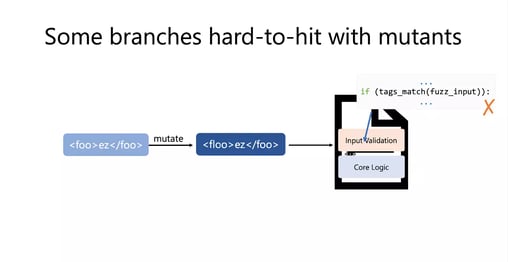
FairFuzz: How to Get Into the Core Logic
FairFuzz is a fuzzer built on top of AFL that makes these mutation strategies a bit less destructive of input structures, and thus, increases the coverage achieved by fuzzers.
First, FairFuzz targets its exploration towards rare branches--- branches that are hit by very few fuzzer generated inputs. Branches that guard core logic will often be rare because most fuzzer-generated inputs don’t satisfy them! So, it selects inputs to mutate only if they hit a rare branch.
 With this target branch in hand, FairFuzz now computes the branch mask. The branch mask should answer the question: “Where can we mutate this input and still hit the target branch?”. We can compute it by flipping each byte in the input and then checking if the mutant with byte flipped at position j still hits the target rare branch. If it does, we mark position j as ok to mutate. Else we mark position j as not ok to mutate!
With this target branch in hand, FairFuzz now computes the branch mask. The branch mask should answer the question: “Where can we mutate this input and still hit the target branch?”. We can compute it by flipping each byte in the input and then checking if the mutant with byte flipped at position j still hits the target rare branch. If it does, we mark position j as ok to mutate. Else we mark position j as not ok to mutate!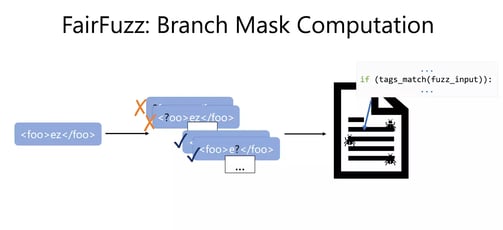
Then, for all future mutants generated from this parent input, FairFuzz only generates mutants at those locations marked “ok to mutate” by the branch mask.

About Caroline
Caroline Lemieux is a PhD Candidate at UC Berkeley in the Department of Computer Science. She aims to help developers improve the correctness, security, and performance of software systems. In her PhD research, she focuses on automatic test-input generation, particularly fuzz testing.
Visit the event recap site to access all slides and recordings from FuzzCon Europe 2020.
